 VIE
VIE +84 9323 494 34
+84 9323 494 34 




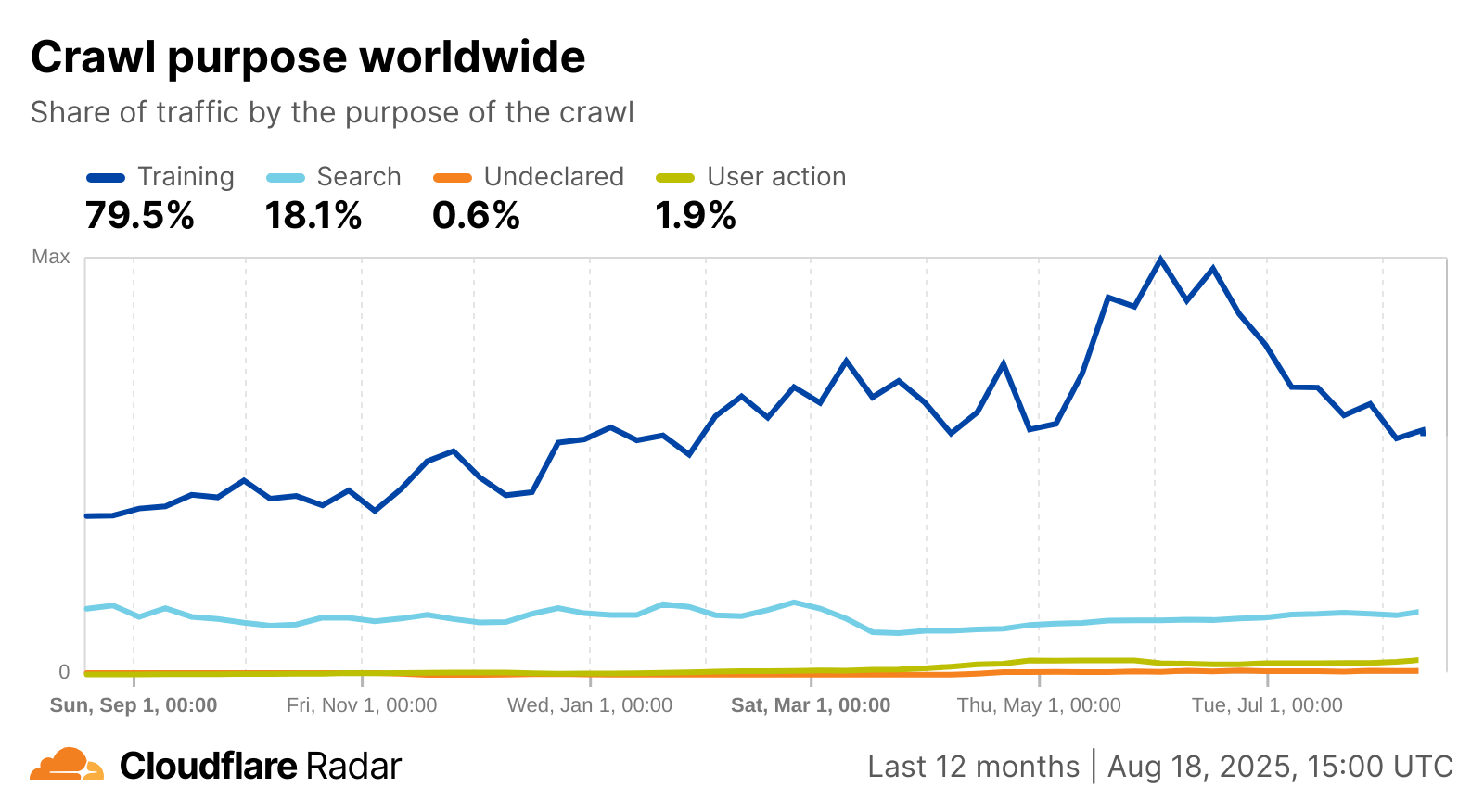
68 Triệu lượt truy cập từ AI hé lộ yếu tố ảnh hưởng đến hiển thị trên AI Search
 Tháng 6 6, 2026
Tháng 6 6, 2026  Uyen Mac
Uyen Mac Nghiên cứu dựa trên 68 triệu lượt truy cập từ AI crawler chỉ ra rằng một mô hình/cấu trúc rõ ràng, mạch lạc giúp của thiện hiệu suất cho website của doanh nghiệp trên AI Search.
Một phân tích mới trên 858.457 website được lưu trữ trên nền tảng Duda cho thấy cách AI crawler đang tương tác với website ở quy mô lớn. Dữ liệu này mang đến góc nhìn rõ ràng hơn về tốc độ tăng trưởng của hoạt động thu thập dữ liệu (crawling), đồng thời chỉ ra những việc mà các chuyên gia SEO và doanh nghiệp cần thực hiện để tăng lượng truy cập đến từ AI Search.
AI Crawling bước vào giai đoạn tăng trưởng lớn
AI crawling đang tăng trưởng nhanh chóng, với số lượng yêu cầu thu thập dữ liệu gắn liền với việc cung cấp câu trả lời theo thời gian thực (real-time answers). Đáng chú ý, phần lớn lưu lượng crawl này đến từ một nhà cung cấp AI duy nhất.
Dữ liệu nghiên cứu cũng cho thấy một mô hình rõ ràng về việc website nào đang được AI crawler truy cập và quan trọng hơn là lý do tại sao chúng được AI ưu tiên thu thập dữ liệu.
Tăng trưởng Referrals Traffic từ các mô hình lớn (LLM) hàng năm
Referral traffic từ các nền tảng LLM đã tăng mạnh trong năm vừa qua, khi nhiều nền tảng ghi nhận mức tăng trưởng đáng kể dù xuất phát từ những mô hình rất khác nhau.
Xu hướng và Mô hình AI Referral Traffic:
- Tổng LLM referrals: Từ 93,484 đến 161,469 (+72.7%)
- ChatGPT: Từ 81,652 đến 136,095 (+66.7%)
- Claude: Từ 106 đến 2,488 (tăng trưởng 23 lần)
- Copilot: Từ 22 đến 9,560 (tăng trưởng mạnh từ con số 0)
- Perplexity: Từ 11,533 đến 13,157 (+14.1%)
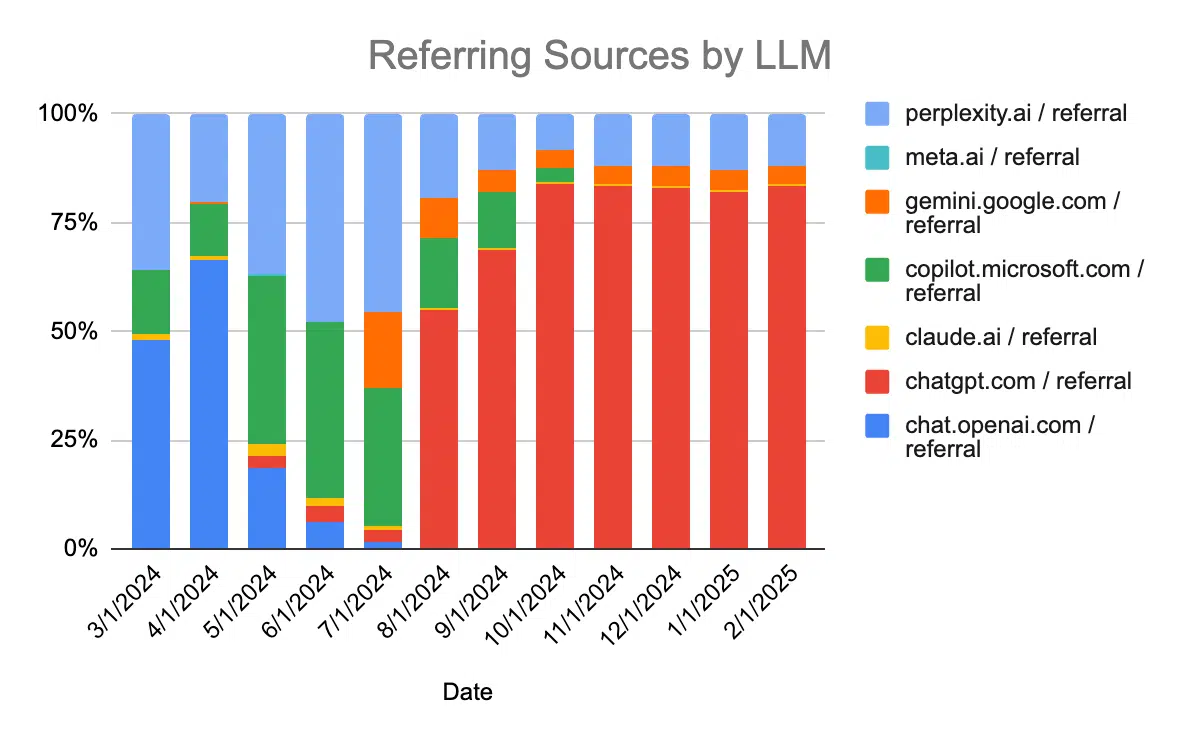
Tốc độ tăng trưởng không diễn ra đồng đều giữa các nền tảng, nhưng nhìn chung, traffic đến từ các hệ thống AI đều đang gia tăng. Xu hướng này cho thấy người dùng tìm kiếm, khám phá nội dung thông qua AI đang trở thành nguồn traffic ngày càng quan trọng, thay vì chỉ là một kênh bổ trợ nhỏ lẻ.
AI Crawlers thu thập nhiều nội dung để cung cấp câu trả lời
AI crawler không còn chủ yếu được sử dụng cho mục đích lập chỉ mục (indexing). Phần lớn hoạt động hiện nay tập trung vào việc truy xuất nội dung theo thời gian thực nhằm cung cấp câu trả lời cho người dùng.
Hầu hết hoạt động thu thập dữ liệu hiện diễn ra để phản hồi các truy vấn của người dùng thay vì hướng đến hoạt động chỉ mục tìm kiếm cho website, điều này làm thay đổi cách thức truy cập nội dung được và cách nội dung được sử dụng.
- User Fetch (câu trả lời thời gian thực): Chiếm 56,9% hoạt động crawler, gần như hoàn toàn đến từ ChatGPT.
- Training (Huấn luyện và đào tạo mô hình): Chiếm 28,8%, được phân bổ giữa GPTBot và các mô hình crawler khác.
- Discovery (Lập chỉ mục nội dung): Chiếm 14,3%, phân bổ giữa nhiều hệ thống khác nhau.
- ChatGPT User Fetch (Khối lượng truy xuất người dùng ChatGPT): Khoảng 39,8 triệu lượt truy cập.
Các xu hướng này chủ yếu đến từ ChatGPT, nền tảng chịu trách nhiệm cho gần như toàn bộ hoạt động truy xuất nội dung theo thời gian thực. Nghĩa là sự chuyển dịch sang hình thức crawling phục vụ trả lời câu hỏi không diễn ra đồng đều trên thị trường mà tập trung vào một nền tảng đang định hình cách thức truy cập nội dung. Xu hướng này có thể thay đổi với sự xuất hiện của crawler Google-Agent mới từ Google.
Mức độ tập trung thị trường (Market Concentration) trong AI Crawling
Hoạt động AI crawling hiện chiếm phần lớn trên công cụ tìm kiếm, đa số thuộc về OpenAI khi phải tiếp nhận và trả kết quả tìm kiếm cho các truy xuất của người dùng. Điều này phản ánh vị thế của Open AI, cũng như công cụ mà người dùng thường sử dụng để tìm kiếm và nhận thông tin.
- OpenAI: 55.8 triệu lượt truy cập (81.0%)
- Anthropic (Claude): 11.5 triệu (16.6%)
- Perplexity: 1.3 triệu (1.8%)
- Google (Gemini): 380,000 (0.6%)
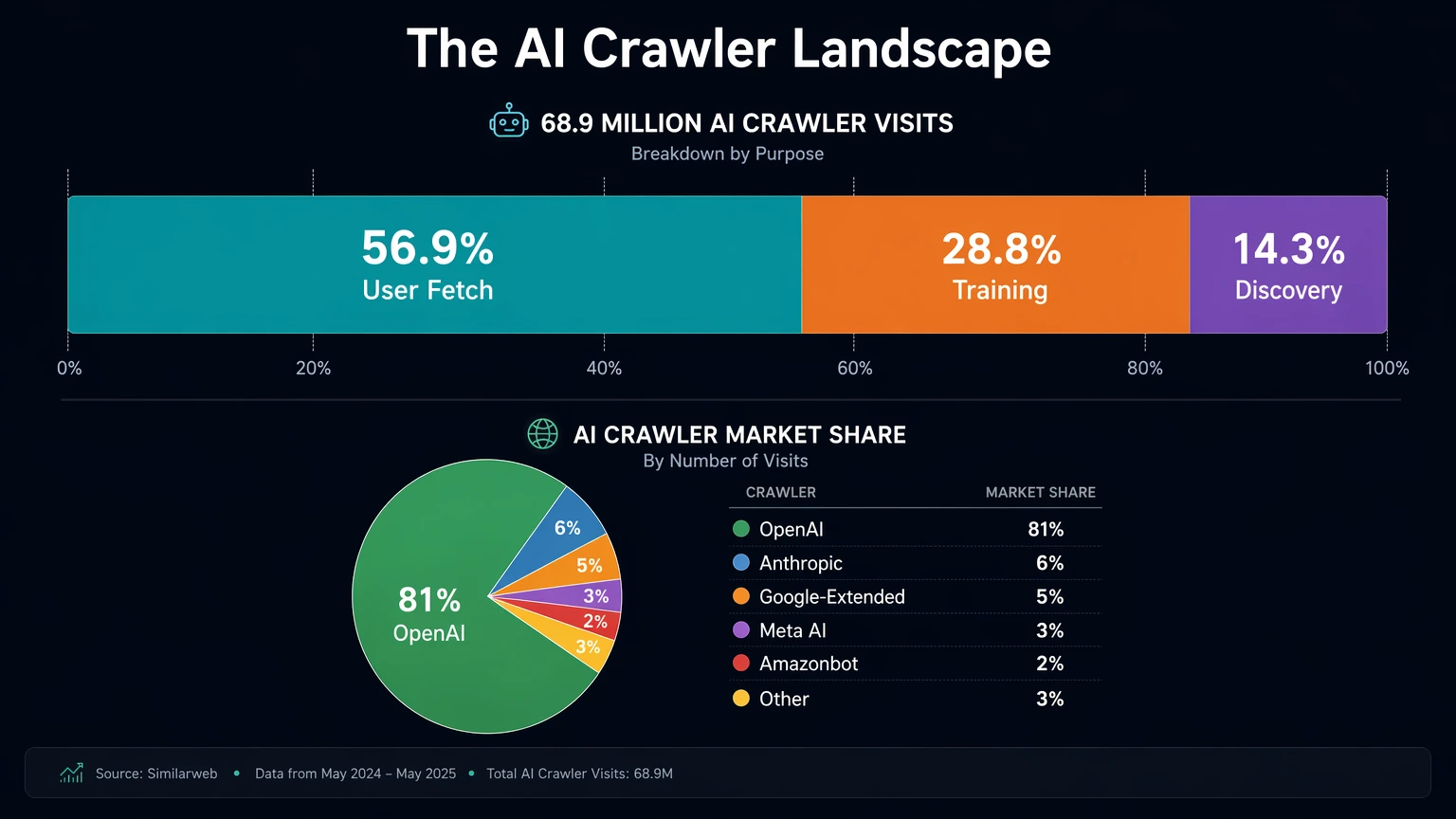
Phần lớn hoạt động AI crawling đến từ OpenAI, phù hợp với vai trò của ChatGPT – công cụ chính để tìm kiếm và truy xuất thông tin. Claude đứng thứ hai với tỷ trọng nhỏ hơn, cho thấy mô hình sử dụng khác biệt, trong khi phần còn lại của thị trường chỉ chiếm tỷ lệ rất nhỏ trong tổng hoạt động crawling.
Quy mô và ý nghĩa đằng sau của AI Crawler
AI crawling hiện đã hoạt động trên quy mô lớn trên toàn bộ web, tiếp cận hàng trăm nghìn website và tạo ra hàng chục triệu yêu cầu mỗi tháng.
Hơn một nửa số website trong tập dữ liệu (dataset) đã nhận được ít nhất một lượt truy cập từ AI crawler, cho thấy hoạt động này không chỉ giới hạn ở nhóm website nhỏ.
- Tổng website đã phân tích: 858,457
- Website nhận ít nhất một lượt truy cập từ AI crawler: 506,910 (59%)
- Tổng lượt truy cập AI crawler (Tháng 2/2026): 68.9 triệu
AI crawling không chỉ tập trung vào các website nổi bật hoặc có traffic cập lớn mà đã phổ biến rộng rãi, với mức độ hiện diện nhất quán trên hầu hết website hiện nay.
Mối quan hệ giữa Crawling và Traffic thực
Những website cho phép hệ thống AI crawl dữ liệu thường cho thấy mức độ tương tác tốt hơn thông qua nhiều chỉ số.
Dữ liệu cho thấy
- Website cho phép AI crawl nhận được nhiều traffic từ người dùng hơn.
- Website có traffic cao có khả năng crawl nhiều hơn
Website do AI crawl nhận được traffic từ người dùng nhiều hơn đáng kể, 527,7 phiên so với 164,9 phiên ở các website không được crawl. Điều này không chứng minh mối quan hệ nhân quả, nhưng cho thấy sự tương quan rõ ràng giữa khả năng thu hút người dùng và tần suất được AI hệ thống quay lại thu thập dữ liệu.
- Traffic trung bình (website được crawl so với không được crawl): 527,7 so với 164,9 (cao hơn 3,2 lần)
- Số lượt gửi biểu mẫu trung bình: 4,17 so với 1,57 (cao hơn 2,7 lần)
- Click to call trung bình: 8,62 so với 3,46 (cao hơn 2,5 lần
- Website có hơn 10.000 phiên: Tỷ lệ crawl đạt 90.5%
Hệ thống AI không tìm kiếm những website yếu hoặc ít hoạt động để nâng hạng. Thay vào đó, AI liên tục quay lại những website vốn đã thu hút được người dùng. Đối với marketer, thuật toán này đã chuyển hướng từ việc cố gắng “được crawl” sang việc xây dựng nhu cầu thực từ người dùng, bởi khả năng hiển thị trên các hệ thống AI dường như đi theo mức độ quan tâm của thị trường.
Yếu tố nào liên quan đến Crawling trên công cụ tìm kiếm?
Nghiên cứu đã so sánh các website có tích hợp bên thứ ba, có cấu trúc và nội dung chuyên sâu với những website không có các yếu tố này, nhằm xác định những yếu tố ảnh hưởng nhiều nhất đến hoạt động AI crawling và lượng AI referral.
Trong toàn bộ tập dữ liệu, 59% website nhận được ít nhất 1 lượt AI crawler truy cập trong tháng 2/2026. Các website được crawl thường xuyên hơn thường sở hữu đồng thời 3 nhóm tín hiệu: tích hợp hệ thống bên ngoài, cấu trúc dữ liệu doanh nghiệp và nội dung chuyên sâu.
1. Tích hợp hệ thống bên ngoài
Các tích hợp này kết nối website với những hệ thống bên ngoài nhằm xác thực và phân phối thông tin doanh nghiệp.
- Yext integration: Tỷ lệ crawl 97.1% so với khoảng 58% ở website không tích hợp (chênh lệch 38.9%)
- Reviews integrations (Tích hợp đánh giá): Tỷ lệ crawl 89.8% so với khoảng 58.8%, trung bình 376.9 lượt crawler truy cập
Website được kết nối với hệ thống dữ liệu và đánh giá bên ngoài được crawl thường xuyên hơn, cho thấy AI sử dụng các tín hiệu này để xác định doanh nghiệp có thật, có thể xác minh và đáng để quay lại.
2. Website có cấu trúc và dữ liệu doanh nghiệp
Các yếu tố dưới đây được tích hợp trực tiếp trên website giúp hệ thống AI hiểu và xác minh danh tính doanh nghiệp.
- Đồng bộ Google Business Profile: Tỷ lệ crawl 92.8% so với 58.9% khi không đồng bộ GMB, trung bình 415.6 lượt crawler truy cập
- Local schema: 72.3% so với 55.2% (chênh lệch 17.1%), với 22.3% doanh nghiệp sử dụng Local schema
- Dynamic pages: 69.4% so với 58.2% (chênh lệch 11.2%)
- Ecommerce: 54.2% so với 59.2% (chênh lệch 5.0%)
Website cho thấy rõ danh tính doanh nghiệp và thể hiện thông tin để máy có thể đọc thường được crawl nhiều hơn, cho thấy AI ưu tiên các website dễ hiểu, dễ xác minh và dễ trích xuất thông tin.

3. Nội dung chuyên sâu (Khối lượng dữ liệu có thể sử dụng)
Website có nhiều nội dung hơn mang lại nhiều cơ hội hơn cho AI trong việc truy xuất, tham chiếu và tái sử dụng thông tin khi tạo câu trả lời. Website có từ 50 bài blog trở lên, trung bình sẽ nhận được 1.373,7 lượt crawler so với 41,6 lượt ở website không có trang blog (cao hơn khoảng 33 lần)
Các website có nhiều nội dung được crawl thường xuyên hơn đáng kể, cho thấy AI có xu hướng quay lại các nguồn cung cấp lượng thông tin hữu ích để phục vụ quá trình tạo câu trả lời.

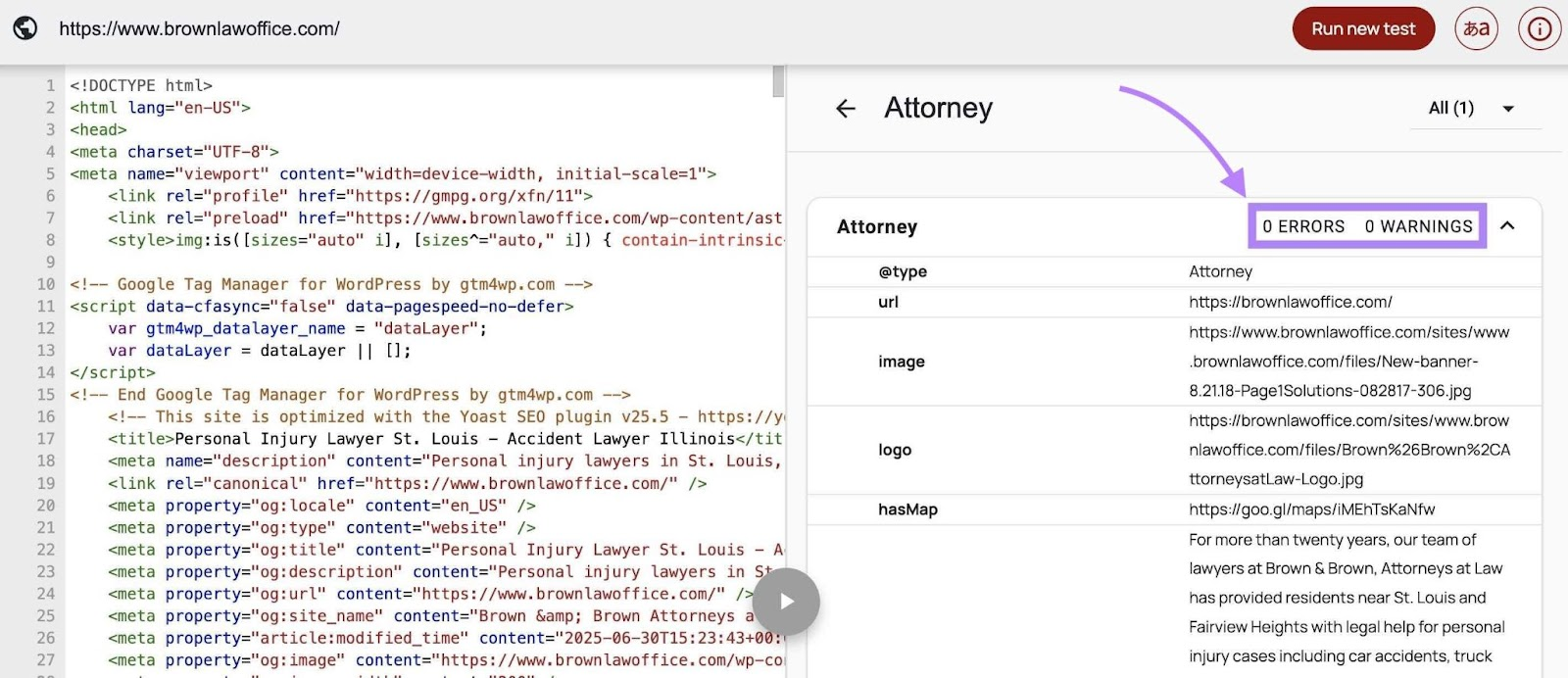
Local Business Schema hoàn chỉnh sẽ nhận Crawling nhiều hơn
Phần nghiên cứu này tập trung vào Local Business Schema, so sánh mức độ hoàn thiện của schema trong việc truyền tải thông tin doanh nghiệp với hoạt động AI crawling. Các trường dữ liệu được đánh giá bao gồm tên doanh nghiệp, số điện thoại, địa chỉ, giờ hoạt động và hồ sơ mạng xã hội.
- Không có trường local schema: Tỷ lệ crawl 55.2%
- Hoàn thành 10 – 11 trường Schema: Tỷ lệ crawl 82%
- Website có Schema hoàn chỉnh hơn đạt tỷ lệ crawl cao hơn 26,8% (82% so với 55,2%)
Các website cung cấp thông tin doanh nghiệp địa phương đầy đủ hơn dưới dạng dữ liệu có cấu trúc được crawl thường xuyên hơn và nhận nhiều lượt crawler truy cập hơn. Khi số lượng trường dữ liệu được hoàn thiện tăng lên, cả tỷ lệ crawl và tần suất crawl đều tăng theo.
Dữ liệu cũng cho thấy khi xác định rõ ràng thông tin doanh nghiệp địa phương, AI dễ dàng nhận diện website hơn. Từ đó, AI sẽ xác minh và quay lại truy cập. Có thể nói, đây là những điều kiện tiên quyết để nhận được traffic từ AI Search.
Tóm tắt những điểm chính
AI crawling đang trở thành một cách thức khám phá nội dung song song với tìm kiếm truyền thống. Nghiên cứu cho thấy các mô hình có cấu trúc rõ ràng ở những website được crawler ghé thăm thường xuyên nhất.
- AI crawling hoạt động song song với tìm kiếm truyền thống, làm thay đổi cách truy cập và tái sử dụng nội dung.
- Website với dữ liệu địa phương rõ ràng, nội dung chuyên sâu và schema hoàn thiện sẽ được AI crawl ghé thăm thường xuyên hơn.
- Nhiều tín hiệu tích cực thường xuất hiện đồng thời trên cùng một website thay vì tồn tại riêng lẻ.
- Dữ liệu chỉ cho thấy xu hướng tương quan, không chứng minh quan hệ nhân quả, nhưng các mô hình cấu trúc website cần nhất quán.
Tóm lại, dữ liệu cho thấy website giúp AI crawler dễ dàng lập chỉ mục và quay lại truy cập thường có hiệu suất tốt hơn. Điểm đáng chú ý ở đây là website cung cấp thông tin rõ ràng, có cấu trúc, có thể xác minh và đồng thời tiếp tục xây dựng/phát triển dựa trên nhu cầu thực từ người dùng sẽ có nhiều khả năng thu hút hệ thống AI ghé thăm lại và hưởng lợi từ traffic do AI Search mang lại.



 Chuyên mục
Chuyên mục  Bài viết gần đây
Bài viết gần đây 












